Data Analytics using Machine Learning/Spark is Hottest Job Technologies

What is Spark?
Spark is an open-source distributed framework. It is one of the fast-in-memory frameworks that is used to process big data. It has over 100 operators working and hence making it easy to transform any type of unstructured data.

Isn’t this interesting? This blog with explain to you How Apache Spark is faster than Hadoop & How it perform Data Analytics using Spark?
All major Hadoop vendors are now supporting spark. Along with this, Spark makes advanced analytics of big data a lot easier and faster.
More and more people have now started using Spark for many reasons. So, if you want to learn more about these technologies. You should probably learn the Spark framework.
What is Spark MLib (MLib means Machine Library used for Analytics)?
Mlib is one of the major components of Spark architecture. The architecture consists of various other important components such as
- Spark core
- Spark Streaming
- Spark SQL
- Spark GraphX
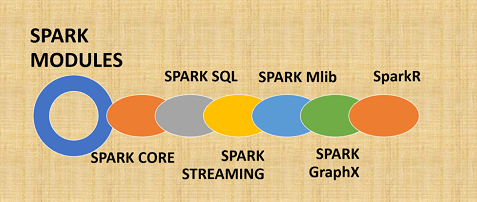
Mib is a library by which Spark is used for Machine Learning. Mlib provides a framework for machine learning. Spark Mlib is popular because of its speed. When compared to other machine learning frameworks Spark Mlib turns out to be very less time-consuming. Developers use Mlib to get the best out of Machine learning and Artificial Intelligence.
How Big Data, Spark & Machine Learning are related?
- Big data is the data that is large and too complex for any normal traditional data processor to process. This data may be as in the number of rows or the complexity of columns.
- As mentioned above, Spark is the open-source framework used to process big data with extreme speed. Just like Hadoop, Spark is a framework used to process these data. As spark is more simple and faster it becomes the best choice for people with Big Data.
- Spark has a library called Mlib (Machine Learning) where it becomes easier to work with Machine Learning using Spark. Therefore, Big data, Spark and Machine learning are related to each other , and having knowledge of all of these is a must.
How Big Data became Leading Technology
- Big data was just the simple technology back in 2008. Soon as the digital transactions and use of the internet for sales and marketing increased people started adopting cloud-based.
- The Cloud The business generates a huge amount of data and more complex data. As more and more people started using these it became hard for the traditional processor to compile and process these data.
- The year 2003: Google first internally used Nutch Search Engine to handle this huge data. Later on, they introduced MR & Big Table for handling its user data (Note: it’s not open-source platform).
- The year 2008: Apache community read the white papers of Google for Big Data Solutions & introduced Open Source Platform in the market called Apache Hadoop.
- The year 2013: Since then some of the best frameworks like Spark and Hadoop are developed to process these data. Later when IoT came into people’s hands, all of them started storing more amount of data with all of their applications and devices. With the use of the frameworks, it became a lot easier to process these data in real-time and hence people started storing more data.
Why Machine Learning Analytics gained vital Importance with Big Data, Spark in 2018-19
Machine Learning is an application of Artificial Intelligence that focuses on building programs that can access data & automatically interpret to situations. We prefer Spark MLib when we require Big Data Analytics (large data sets).

For these reasons, not only in 2018-19 but also in the future the industry will need Big Data, Machine Learning, and Spark resources.
Topics to study in Big Data, Machine Learning, and Spark
Now when it comes to learning about these technologies. People often get confused on what to study and from where you can get started. Below given are some topics you must need to learn to master these technologies?
Big Data
- Fundamentals of Big data include what is Big data and how to get started
- Distributed file system. You can start with HDFS
- Distributed processing engines in big data like Map Reduce, Spark
- Data ingestion tools you can use such as Sqoop, Flume, Pig, HBase, Kafka etc
- Data processing techniques using various languages. Python, Scala and Spark SQL can be learned for getting started.
You can take Big Data Training
Machine Learning
Getting started with Machine learning is easy when you know from where and which topic you should start learning. You can always start by getting to learning the basics of Machine Learning and then go on to the topics.
- Basics of Machine Learning
- Linear Regression with One Variable
- Linear Algebra Review
- Linear Regression with Multiple Variables
- Octave/Matlab
- Logistic Regression
- Regularization
- Neural Networks: Representation
- Neural Networks: Learning
- Machine Learning System Design
- Support Vector Machines (SVM)
- Unsupervised Learning
- Dimensionality Reduction
- Anomaly Detection
- Recommender Systems
- Large Scale Machine Learning
The above mentioned are some of the topics you can learn to know about Machine Learning but it is always better to learn by applying some of them in practical use. You can take Machine Learning Training.
Spark
After getting the fundamentals of Spark, one can master spark according to the way they want to use the Spark.
People interested in Learning Spark for Machine Learning can learn about the Spark Mlib. Some of the topics that can be covered in Mlib are given below.
SPARK MLIB Using STANDARD DATATYPES
In this, you can learn about various other topics such as
- Basic statistics using Spark
- Data sources
- Pipelines
- Extracting, transforming and selecting features
- Classification and Regression
- Clustering
- Collaborative filtering
- Frequent Pattern Mining
- Model selection and tuning
SPARK-MLIB using RDD Based API
- Datatypes
- Basic Statistics
- Classification & Regression
- Linear Methods
- Decision Trees
- Tree Ensembles
- Clustering
- Collaborative Filtering
- Frequent Pattern Matching
- Model Selection & Tuning
- Optimization of Linear Methods can be learned for developers.
SPARK ML(Machine Pipelines) /DataFrame APIs
- ML Dataset
- ML Algorithms
- Transformers
- Estimators
- Properties of ML Algorithms
- ML Pipeline
- Code Examples
- Estimator, Transformer, and Param
- Model Selection via Cross-Validation
These are some of the topics you can learn to get started with the above-given technologies.
However, there are various aspects you need to keep in mind. All of these technologies have many different applications and use.
You should learn the topics depending on how you want to use these technologies in near future.
For developers, there are different programming languages you can use. Python, Java, R, etc are some of the popular languages which are used for these technologies.
You can choose any one of these languages according to which you are comfortable.
Real-Time Industry Applications of Big Data, Machine Learning, Spark
This was all about the importance and the future of these three technologies.
Now let us talk about some of the applications of Big data, Machine learning, and Spark.
Online Fraud Detection: This is one of the best use of technology. By analyzing various spam and suspicious activities one can easily detect online fraud. Various activities such as money laundering can be stopped by Machine Learning and analyzing big data. This is also used for email spam filtering.
Virtual Personal Assistants: Siri, Alexa, Google Assistance all of these assistants use all these technologies. It makes it easier for them to store a large amount of user data and process it automatically. Machine Learning makes it easier to improve them automatically according to the user voice and the way they use the assistants.
Videos Surveillance: Gone are the days where a single person monitors all the cameras. With the growth of these technologies, one can easily keep an eye on all cameras and detect any crime or suspicious activities. It also becomes possible to find a person’s face by this.
Sales, Marketing, and customer service: These technologies have also taken over sales and marketing. A lot of user’s information is processed for the best marketing strategy. Customer service is made easier by filtering the problems and solutions based on user data.
Conclusion
So, to conclude these are the leading technologies and is growing day by day. Today by its growth there are many high-paying jobs for these technologies.
Most of the experts are predicting this year the Job Market for Processing and analyzing big data using Spark and Machine Learning will be the hottest market.
When compared to 2012, today the job market has risen tremendously and is continuing to grow. Hence, not only for 2019 but also for upcoming years the job market will be increasing and the big giants will be ready to pay more money for the experts of these technologies.
Therefore, if you still haven’t mastered Machine Learning, Big data, and Spark, you should start learning them today.
