Big Data Hadoop Tutorial for Beginners

Introduction to Big Data
Big data refer to all the data generated through various platforms across the world. A data is classified as big if the total size is more than 1 GB/TB/PB/EX.
Categories of BigData:
1) Structured
2) Unstructured
3) Semi-structured

Example of BigData:
1) New York Exchange generates about 1 TB of new trade data per day.
2) Social Media: Statistics show that 500+ terabytes of data get ingested into the database of social media site Facebook, every day.
Data mainly generated in terms of
- Photos & video uploads
- Message exchanges
- Putting comments etc.

3) Jet Engine /Travel Portals:
Single Jet Engine generates 10+ terabytes(TB) of data in 30 minutes of a flights per day. Generation of data reaches up to many Petabytes (PB).

What is Hadoop?
Hadoop is an open-source framework managed by The Apache Software Foundation. Open source implies that it is freely available and its source code can be changed as per the requirement. Apache Hadoop is designed to store & process big data efficiently. Hadoop is used for data storing, processing, analyzing, accessing, governance, operations & security.
Large organization with a huge amount of data uses Hadoop software, processed with the help of a large cluster of commodity hardware. Cluster term refers to a group of systems that are connected via LAN and multiple nodes on this cluster helps in performing the jobs. Hadoop has gained popularity worldwide in managing big data and at present, it has covered nearly 90% market of big data.
Suggested Read:- DIFFERENCE BETWEEN DATA SCIENCE, DATA ANALYTICS AND MACHINE LEARNING
Features of Hadoop:

- Cost-Effective: Hadoop system is very cost-effective as it does not require any specialized hardware and thus requires low investment. The use of simple hardware known as commodity hardware is sufficient for the system.
- Supports Large Cluster of Nodes: A Hadoop structure can be made of thousands of nodes making a large cluster. Large cluster helps in expanding the storage system & offers more computing power.
- Parallel Processing of Data: Hadoop system supports parallel processing of the data across all nodes in the cluster, and thus it reduces the storage & processing time.
- Distribution of Data(Distributed Processing): Hadoop efficiently distributes the data across all the nodes in a cluster. Moreover, it replicates the data over the entire cluster in order to retrieve the data from other nodes, if a particular node is busy or fails to operate.
- Automatic Failover Management (Fault Tolerance): An important feature of Hadoop is that it automatically resolves the problem in case a node in the cluster fails. The framework itself replaces the failed system with another system along with configuring the replicated settings & data on the new machine.
- Support Heterogeneous Cluster: the Heterogeneous cluster is one that accounts for nodes or machines which are from a different vendor, different operating system and running at different versions. For instance, if a Hadoop cluster has three systems, one IBM machine that runs on RHEL Linux, the second is INTEL machine running on Ubuntu Linux and third is AMD machine running on FEDORA Linux. All of these different systems are capable to run simultaneously on a single cluster.
- Scalability: A Hadoop system has the ability to add or remove node/nodes and hardware components from a cluster, without affecting the operations of the cluster. This refers to scalability, which is one of the important features of the Hadoop system.
Must Read:- WHY BIG DATA WITH PYTHON IS TOP TECH JOB SKILL
Overview of Hadoop Ecosystem:
The Hadoop ecosystem consists of
1) HDFS (Hadoop Distributed File System)
2) Apache MapReduce
3) Apache PIG
4) Apache HBase
5) Apache Hive
6) Apache Sqoop
7) Apache Flume, and
8) Apache Zookeeper
9) Apache Kafka
10) Apache OOZIE
These components of the Hadoop ecosystem are explained as follows:
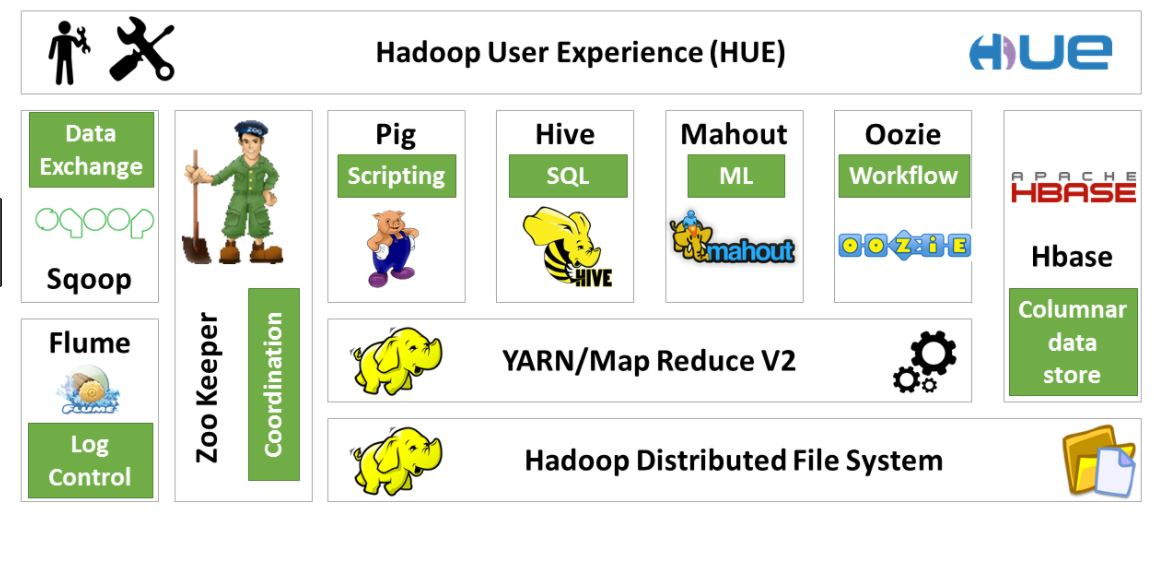
- HDFS (Hadoop Distributed File System): HDFS has the most important job to perform in the Hadoop framework. It distributes the data and stores them on each node present in a cluster simultaneously. This process reduces the total time to store data onto the disk.
- MapReduce (Read/Write Large Datasets into/from Hadoop using MR) : Hadoop MapReduce another most important part of the system that processes the huge volume of data stored in a cluster. It allows parallel processing of all the data stored by HDFS. Moreover, it resolves the issue of the high cost of processing through the massive scalability in a cluster.
- Apache PIG (PIG is a kind of ETL for Hadoop Ecosystem): It is the high-level scripting language to write the data analysis programs for huge data sets in the Hadoop cluster. Pig enables the developers to generate query execution routines for the analysis of large data sets. The scripting language is known is Pig Latin which one key part of Pig & the second key part is a
- Apache HBase (OLTP/NoSQL) sources: It is a column-oriented database that supports the working of HDFS on real-time basis. It is enabled to process large database tables i.e. a file containing millions of rows & columns. An important use of HBase is the efficient use of master nodes for managing region servers.
- Apache Hive (HIVE is SQL Engine on Hadoop): It is a language similar to SQL, which allows the squaring of data from HDFS. The Hive version of SQL language is called as HiveQL.
- Apache Sqoop(Data Import/Export from RDBMS(SQL sources) into Hadoop): It is an application that helps in import & export of data from Hadoop to other relational database management systems. It can transfer the bulk of data. Sqoop is based on connector architecture that backs the plugins for establishing connectivity to new external systems.
- Apache Flume(Data Import from Unstructured(Social Media sites)/Structured into Hadoop) : It is an application it allows the storage of streaming data into the Hadoop cluster, such as data being written to log files is a good example of streaming data.
- Apache Zookeeper ( Co-ordination tool used in a Clustered environment (Hadoop)): Its role is to manage the coordination between the above-mentioned applications for their efficient functioning in the Hadoop ecosystem.
Functioning of Hadoop – HDFS Daemons
Hadoop system works on the principle of master-slave architecture. HDFS daemons consist of the following:
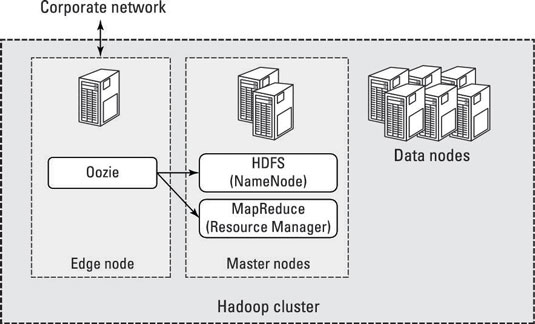
- Name Node: It is the master node, and is single in the It is responsible for storing HDFS Metadata that keeps track of all the files that are stored in the HDFS. The information stored on Metadata is like the file name, file permission it has, authorized user of the file & the location where it is stored. This information is stored on RAM which is generally called as file system Metadata.
- Data Nodes: It is the slave node, and is present in multiple numbers. Data nodes are responsible for storing & retrieving the data as instructed by the name node. Data nodes intermittently report to the name node with their present status & all the files stored with them. The data nodes keep multiple copies of each file stored in them.
- Secondary Name Node: Secondary name node is present to support the primary name node in storing the Metadata. On the failure of name node due to corrupt Metadata or any other reason secondary name nodes prevent the dysfunctioning of the complete cluster. The secondary name node instructs the name node to create & send fsimage & editlog file, upon which the compacted fsimage file is created by the secondary name node. This compacted file is then transferred back to name node and it is renamed. This process repeats after every 1 hour or when the size of editlog file exceeds 64MB.
The functioning Hadoop system can be better understood with the help of a live example. Let us take the example of a banking system.
Banks are required to analyze loads of unstructured information with them which is collected through various sources such as social media profiles, calls, complaint logs, emails, discussion forums, and also through traditional sources of collecting information like cash and equity, transactional data, trade, and lending, etc. for better understanding & analyzing the customers.
The financial firms are now adopting the Hadoop system in order to structurally store the data, access the data, and analyzing & extracting the key information from the data that will provide comprehensive insights to help to make the right & informed decision.
Join Gyansetu’s Big Data Hadoop Training in Gurgaon for the best career.
