5 Best Big Data Tools You Must Know

Data – a four-lettered word that makes the world go round.
As per research conducted by DOMO, “Over 2.5 quintillion bytes of data are created every single day, and it’s only going to grow from there. By 2020, it’s estimated that 1.7MB of data will be created every second for every person on earth.”

An increase in the number of users of the internet and influx of data has also made things simpler for businesses. An economic environment is made up of transactions between consumers and businesses. Similarly, a business organization is nothing without its human resource.
Interaction between these resources is streamlined and made simpler with the help of data analysis.
As rightly said by Atul Butte in Stanford, “Hiding within those mounds of data is knowledge that could change the life of a patient, or change the world.”
If these sentences do not make any sense to you, let us tell you how data can help businesses –
- With the help of collected data of consumers, your business can redesign its marketing strategies to achieve better results.
- Through data, your business can hire better resources with the help of online tools.
- Data can help your business predict future trends and modify your plans as per them.
- Data can also help in personalizing the experience of your consumers, thereby, increasing their satisfaction.
However, the question which arises now is that if there’s a sea of data being generated every minute, how does a business reach a decision with its help?
This is where Big Data comes in.
WHAT IS BIG DATA?
In simple words, big data is data generated from various sources and through different formats. Thanks to the amount of information available on internet, the accumulated data is growing exponentially every day. Big data is primarily defined through Vs.
Let us tell you what they are –
- VELOCITY: Data flows in higher velocity and speed than in earlier times. The number of internet users have helped in accelerating the pace.
- VARIETY: From pictures, videos to information and numbers, the type of data pouring in through various channels is varied as it can get
- VOLUME: The amount of data generated every minute is growing in leaps and bound. As per statistics, the average amount of data generated every minute is US alone is 2,657,700 gigabytes.
As data has been multiplied hundreds of times, its analysis has become even more difficult.
Data comes in all kinds of forms – structured and unstructured. To make this data useful by drawing information and insights, we need systems which are much more advanced than traditional databases.
This is where Big Data tools and analytics come in.
“Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway.” – (Geoffrey Moore, author and consultant)
In this article, we will walk you through some of the best big data tools to look out for in 2019
TOP BIG DATA TOOL YOU MUST KNOW
-
HADOOP:
If there’s a discussion about big data, it is incomplete without a mention of Hadoop. Literally, Hadoop and big data are inseparable. Even in 2019, Hadoop remains significant and relevant in the world of Big Data analytics.
SO, WHAT IS HADOOP?
- Hadoop is an open-source framework that helps in storing data and tackling big data in an efficient way. It first came into existence in early 2000s; around the same time as Google.
It began as a search engine indexing tool and grew more technical with features like storing and processing data. Over time, hadoop has become synonymous with big data analytics and still remains important. It is low cost and has easy accessibility.
It has four components –
Hadoop Common: basic utilities for every kind of case.
Hadoop Distributed File System (HDFS): a database for storing data in a simple manner
Hadoop MapReduce: Helps in processing and simplifying a large set of data by filtering and analysis.
Hadoop YARN: helps in resource management and scheduling.
Even though, it is as old as the term “Big Data”, it still remains the backbone of it. Thanks to its affordability, open libraries and scalability, Hadoop still has a growing scope in 2019.
Learning Hadoop will give you a solid base and understanding of Big Data. It will also help you in learning other technologies like Apache Spark etc.
-
APACHE SPARK:
Developed in 2009 at UC Berkeley, Apache Spark is one of the most popular open-source data processing engines with APIs in varied forms like Java, Python, SQL and R. Apache Spark was developed to provide speed, ease of use and sophisticated analysis.
In an article in Forbes, Apache Spark was called Taylor Swift of Big data as it has been around for a while but grabbed eyeballs only around 2015.
In the past few years, Apache Spark has gained a lot of admirers mainly because of the following reasons
– It uses electronic memory rather than completely relying on hard disk which makes it 10 times faster. - Even though it doesn’t have its own database, it can easily be integrated with any system like HDFS, MongoDB and Amazon’s S3 system.
- It is the most preferred framework for Machine Learning. Machine Learning is the present and the future of technology.
- With the help of Spark Streaming, data can be analyzed in real-time.
Apache Spark was developed as an improvisation of Hadoop and is still flourishing. It is now considered as one of the key and mature tools for Big Data Analytics.
Even with introductions of new technology, Apache Spark continuous to rule the Big Data ecosystem.
-
APACHE CASSANDRA:
The software world runs on scalability. And, Apache Cassandra is a highly scalable, no SQL, open-source framework.
Open-sourced in 2008 by Facebook, Apache Cassandra provides certain advantages that no other relational database or SQL can give. Some of these advantages are –
– DECENTRALIZATION: Apache Cassandra doesn’t have a master-slave architecture. Every cluster is identical eliminating a single point of failure or network bottlenecks.
– HIGHLY ELASTIC: Its unique decentralized architecture makes adding new nodes easy, thus, enables it to handle a large amount of data across channels.
– LINEAR SCALABILITY: Scaling is easier and simpler as no single node is interdependent on each other, and adding a new node can help you scale as much as you would like.
Apache Cassandra has been helping big shots like Apple, Spotify, Instagram, ebay etc. Its ability to handle multiple concurrent users without affecting the performance makes it the first choice of many organizations.
In 2019, Apache Cassandra will only continue to grow as more and more people realize its benefits.
-
MongoDB:
Just like Apache Cassandra, Mongo DB is another NoSQL database. With its high flexibility, cost-effectiveness and open-source libraries, Mongo DB is the fastest growing technology. It is simple, dynamic and object-oriented.
What makes it different from the traditional databases is its document store model in which data is stored as a document rather than in columns of a traditional database.
Some of the advantages it offers are
– Because of its rich document-based data system in the form of BSON etc, a large variety of data like integer, string, array can easily be stored.
– Its infrastructure is cloud-based making it highly flexible.
– It uses dynamic schemas which allows data to be set up quickly. This helps in saving cost and time
– It helps in the real-time analysis of data.
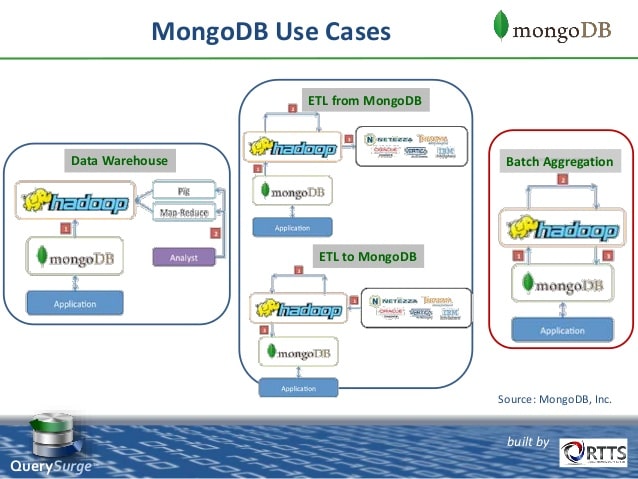
Mongo DB is highly preferred for e-commerce websites, social networking sites and content management. All of these are the need of the hour in 2019. As the most important part of MEAN Stack, it is the most preferred framework by startups. Moreover, bigger companies too are adopting it quickly.
-
APACHE SAMOA :
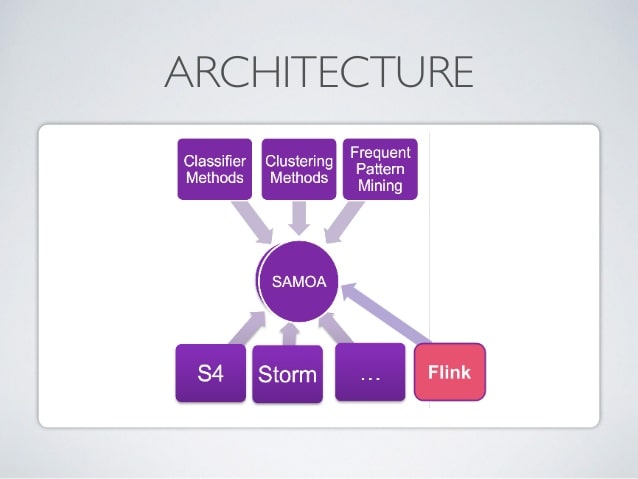
Coming back to the Apache family, Apache SAMOA is one of the most popular big data tools especially for the graphical databases.

- SAMOA stands for Scalable Advanced Massive Online Analysis and really, the abbreviation explains it all.Apache SAMOA is an open-source platform which has a collection of the distributed streaming algorithm for data mining and machine learning tasks such as –-Regression,
-Clustering
-Classification
-Program AbstractionIt has a pluggable architecture which allows it to run on many distributed stream processing engines like –
– Apache Storm
– Apache S4
– Apache FlinkApache Samoa is the most preferred framework for Machine learning as it facilitates the development of new machine learning algorithms without interfering with the complexity of underlying distributed stream processing. Some major reasons why it is preferred are
– With its pluggable and reusable architecture, deployment becomes easy.
– There’s no downtime.
– Once a program is completed, it can be run everywhere.
– Simple process.
CONCLUSION:
Big Data is the biggest trend of 2019 and of the coming future. An understanding and proficiency in big data help in carving a bankable career path for yourself. Our suggestion would be to begin your journey in Big Data with Hadoop and Spark.
These two technologies are a pioneer in the world of Big Data and will always remain the basis of analytics. For more information, feel free to contact us and check our training program.
