Interview Questions
Questions
There are three types of machine learning:
import numpy np.eye(3)| HFSHFJ | JWDJW |
| DSDW | djskjdsk |
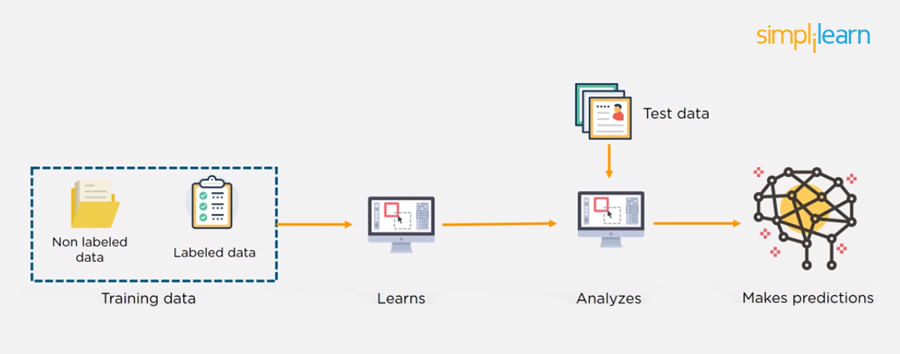
Supervised Learning
In supervised machine learning, a model makes predictions or decisions based on past or labeled data. Labeled data refers to sets of data that are given tags or labels, and thus made more meaningful.
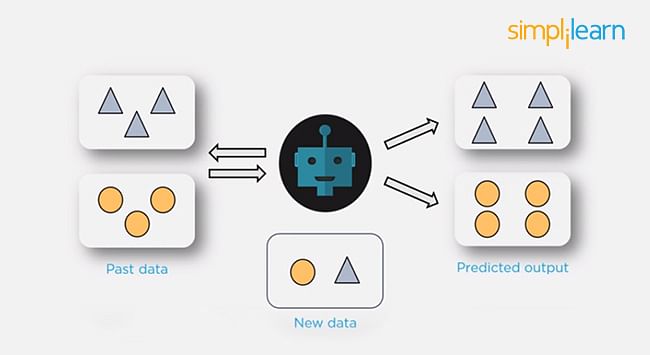
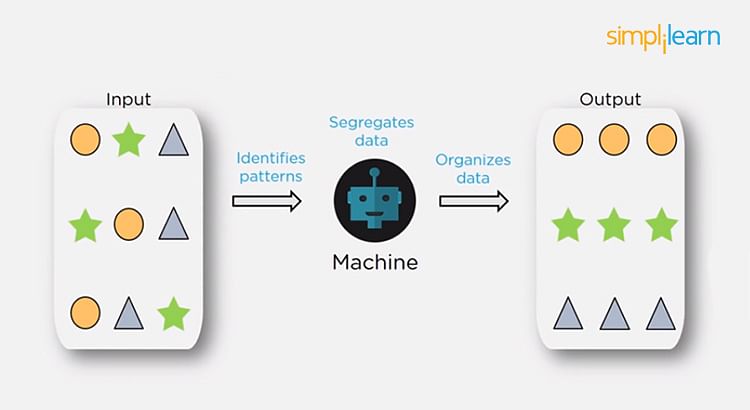
Unsupervised Learning
In unsupervised learning, we don't have labeled data. A model can identify patterns, anomalies, and relationships in the input data.
Reinforcement Learning
Using reinforcement learning, the model can learn based on the rewards it received for its previous action.
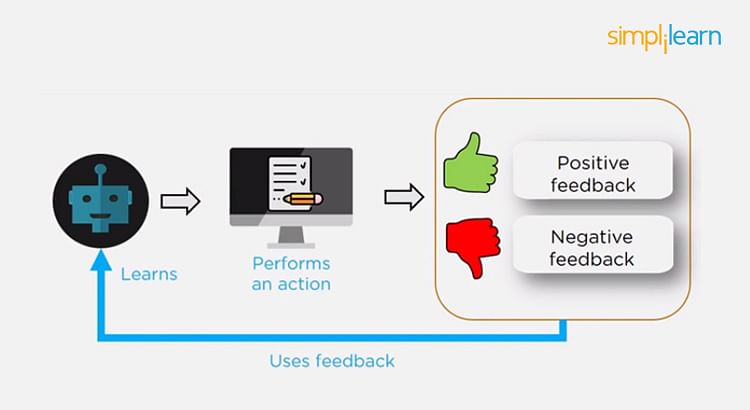
Consider an environment where an agent is working. The agent is given a target to achieve.
Every time the agent takes some action toward the target, it is given positive feedback. And, if the action taken is going away from the goal, the agent is given negative feedback.
- Regularization. It involves a cost term for the features involved with the objective function
- Making a simple model. With lesser variables and parameters, the variance can be reduced
- Cross-validation methods like k-folds can also be used
- If some model parameters are likely to cause overfitting, techniques for regularization like LASSO can be used that penalize these parameters
- Shalki Aggarwal
- Sahil Aggarwal
- dsgs
- retretre
- sadsadas
- We provide interaction with faculty before the course starts.
- Our Train the Trainer approach ensures you learn proactively and come out as an expert.
Overfitting is a situation that occurs when a model learns the training set too well, taking up random fluctuations in the training data as concepts. These impact the model’s ability to generalize and don’t apply to new data.
When a model is given the training data, it shows 100 percent accuracy—technically a slight loss. But, when we use the test data, there may be an error and low efficiency. This condition is known as overfitting.
There are multiple ways of avoiding overfitting, such as:
djsjdjk
check now
1. Concepts of MapReduce framework & HDFS filesystem.
2. Setting up of Single & Multi-Node Hadoop cluster.
3. Understanding HDFS architecture.
4. Writing MapReduce programs & logic
- Train the model
- Test the model
- Deploy the model
- The training set is examples given to the model to analyze and learn
- 70% of the total data is typically taken as the training dataset
- This is labeled data used to train the model
- The test set is used to test the accuracy of the hypothesis generated by the model
- Remaining 30% is taken as testing dataset
- We test without labeled data and then verify results with labels
There is a three-step process followed to create a model:
| Training Set | Test Set |
|---|---|
Consider a case where you have labeled data for 1,000 records. One way to train the model is to expose all 1,000 records during the training process. Then you take a small set of the same data to test the model, which would give good results in this case.
But, this is not an accurate way of testing. So, we set aside a portion of that data called the ‘test set’ before starting the training process. The remaining data is called the ‘training set’ that we use for training the model. The training set passes through the model multiple times until the accuracy is high, and errors are minimized.
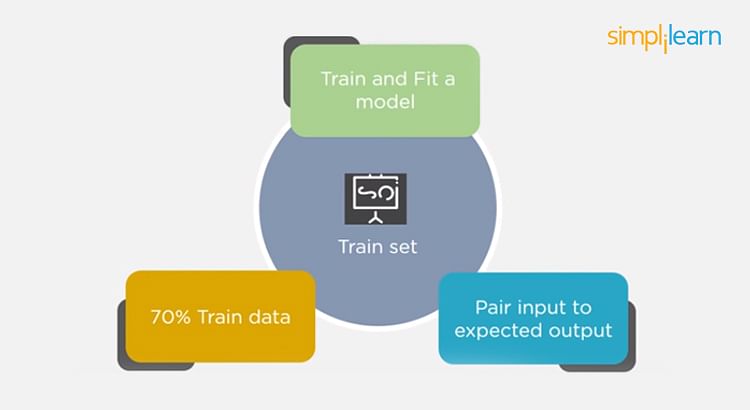
Now, we pass the test data to check if the model can accurately predict the values and determine if training is effective. If you get errors, you either need to change your model or retrain it with more data.
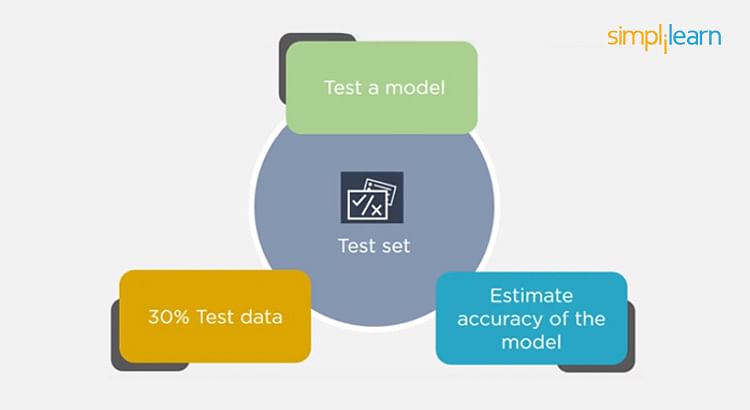
Regarding the question of how to split the data into a training set and test set, there is no fixed rule, and the ratio can vary based on individual preferences.
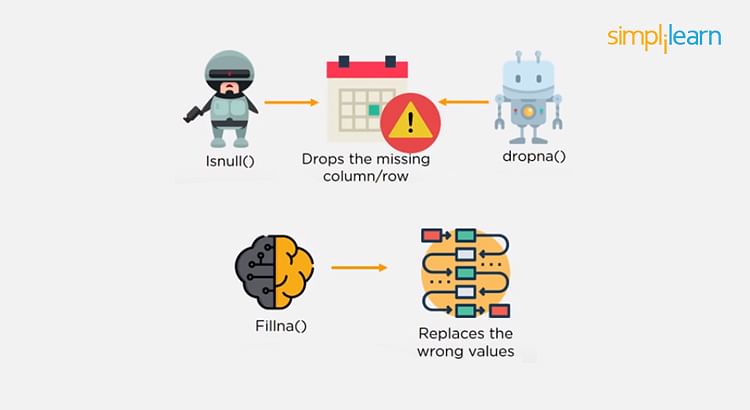
- IsNull() and dropna() will help to find the columns/rows with missing data and drop them
- Fillna() will replace the wrong values with a placeholder value
One of the easiest ways to handle missing or corrupted data is to drop those rows or columns or replace them entirely with some other value.
There are two useful methods in Pandas:
 ???????
???????
When the training set is small, a model that has a right bias and low variance seem to work better because they are less likely to overfit.
For example, Naive Bayes works best when the training set is large. Models with low bias and high variance tend to perform better as they work fine with complex relationships.
- Actual
- Predicted
A confusion matrix (or error matrix) is a specific table that is used to measure the performance of an algorithm. It is mostly used in supervised learning; in unsupervised learning, it’s called the matching matrix.
The confusion matrix has two parameters:
It also has identical sets of features in both of these dimensions.
Consider a confusion matrix (binary matrix) shown below:
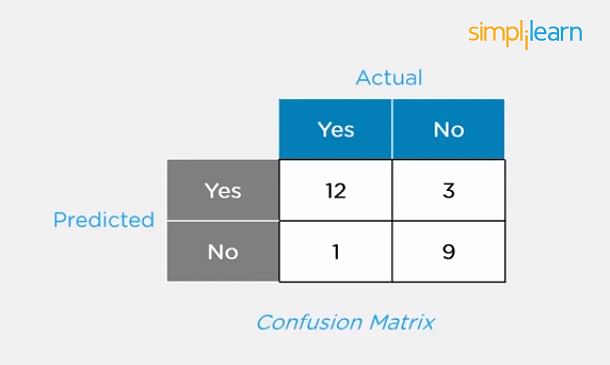
Here,
For actual values:
Total Yes = 12+1 = 13
Total No = 3+9 = 12
Similarly, for predicted values:
Total Yes = 12+3 = 15
Total No = 1+9 = 10
For a model to be accurate, the values across the diagonals should be high. The total sum of all the values in the matrix equals the total observations in the test data set.
For the above matrix, total observations = 12+3+1+9 = 25
Now, accuracy = sum of the values across the diagonal / total dataset
= (12+9) / 25
= 21 / 25
= 84%
False positives are those cases which wrongly get classified as True but are False.
False negatives are those cases which wrongly get classified as False but are True.
In the term ‘False Positive,’ the word ‘Positive’ refers to the ‘Yes’ row of the predicted value in the confusion matrix. The complete term indicates that the system has predicted it as a positive, but the actual value is negative.

So, looking at the confusion matrix, we get:
False-positive = 3
True positive = 12
Similarly, in the term ‘False Negative,’ the word ‘Negative’ refers to the ‘No’ row of the predicted value in the confusion matrix. And the complete term indicates that the system has predicted it as negative, but the actual value is positive.
So, looking at the confusion matrix, we get:
False Negative = 1
True Negative = 9
Model Building
Choose a suitable algorithm for the model and train it according to the requirementModel Testing
Check the accuracy of the model through the test dataApplying the Model
Make the required changes after testing and use the final model for real-time projects
The three stages of building a machine learning model are:
Here, it’s important to remember that once in a while, the model needs to be checked to make sure it’s working correctly. It should be modified to make sure that it is up-to-date.

Deep learning is a subset of machine learning that involves systems that think and learn like humans using artificial neural networks. The term ‘deep’ comes from the fact that you can have several layers of neural networks.
One of the primary differences between machine learning and deep learning is that feature engineering is done manually in machine learning. In the case of deep learning, the model consisting of neural networks will automatically determine which features to use (and which not to use).
- Enables machines to take decisions on their own, based on past data
- It needs only a small amount of data for training
- Works well on the low-end system, so you don't need large machines
- Most features need to be identified in advance and manually coded
- The problem is divided into two parts and solved individually and then combined
- Enables machines to take decisions with the help of artificial neural networks
- It needs a large amount of training data
- Needs high-end machines because it requires a lot of computing power
- The machine learns the features from the data it is provided
- The problem is solved in an end-to-end manner
| Machine Learning | Deep Learning |
|---|---|
Supervised learning uses data that is completely labeled, whereas unsupervised learning uses no training data.
In the case of semi-supervised learning, the training data contains a small amount of labeled data and a large amount of unlabeled data.