What are the Top 5 Machine Learning Algorithms every Data Scientist Must know by heart

Machine Learning is the last invention that humanity needs to make” – Nick Bostrom
Real-time cases of machine learning:
- You look for a product on an e-commerce site and you receive suggestions of products you may like.
- You start to type a text message to your friend, and your texts get predicted as per your last conversation.
Few years back, who would have thought about the intelligence our machines would start to show?
To put it in very simple words, machine learning is a subset of artificial intelligence that enables the system to learn through experiences, iteration and repeated human behavior rather than being specifically, explicitly programmed.
Most of the phenomenon around us which makes us amazed and flustered, like incessant type suggestions and reminders of discounts on the products we may have checked out once are a result of machine learning.
If you’re still undermining the power of machine learning, let us introduce you to few statistics in order to prove us wrong-
- As per predictions, by 2021, 85% of customer interactions will not require a human.
- Around 7% of the population aged between 12+ own an AI-based speaker device like an Amazon Echo and Google Home Devices.
Machine learning is steadily becoming a huge part of our conscience. In this article, we will explore how machine learning works and how it is influenced.
HOW DOES MACHINE LEARNING WORK?
There are three techniques used by machine learning, namely –
- Supervised learning: Using known input and output data to train a model for making predictions. Whether a mail is spam or not is an example of classification technique in supervised learning where data can be tagged or grouped. Prediction of temperature is an example for regressive technique where data is a real number.
- Unsupervised learning: Finding latent patterns in input data to make predictions. The main difference between supervised and unsupervised learning is the avialability of a precise input data.
- Reinforcement learning: Getting trained by the environment with a reward system to choose a best possible output with a given set of input.
The working of machine learning hugely depends upon various algorithms. An algorithm, basically, is a step-by-step process of filtering data in order to reach a particular outcome. The basic function of machine learning is improving predictions with the help of data and its behavior.
Algorithms are the core of machine learning and here’s why –
- Machine learning is about training a system to learn and provide an output. Algorithms helps in providing a structured design for the given inputs to provide a coherent output.
- When we learn to drive, we train our mind to take various action under different situations. Algorithms teach systems to behave in a certain way when confronted by a set of instructions.
- Essentially, every computer program has an underlying algorithm which dictates its working and machine learning is no different.
Over time, Machine learning has evolved than what it had started as. Most of its accuracy and success depends upon the algorithms.
Here Top 5 Machine Learning Algorithms every Data Scientist should Must by heart
-
DECISION TREE ALGORITHM
-
K MEANS CLUSTERING ALGORITHM
-
LINEAR REGRESSION
-
RANDOM FOREST ALGORITHM
-
NAÏVE BAYES ALGORITHM
1) DECISION TREE ALGORITHM:-
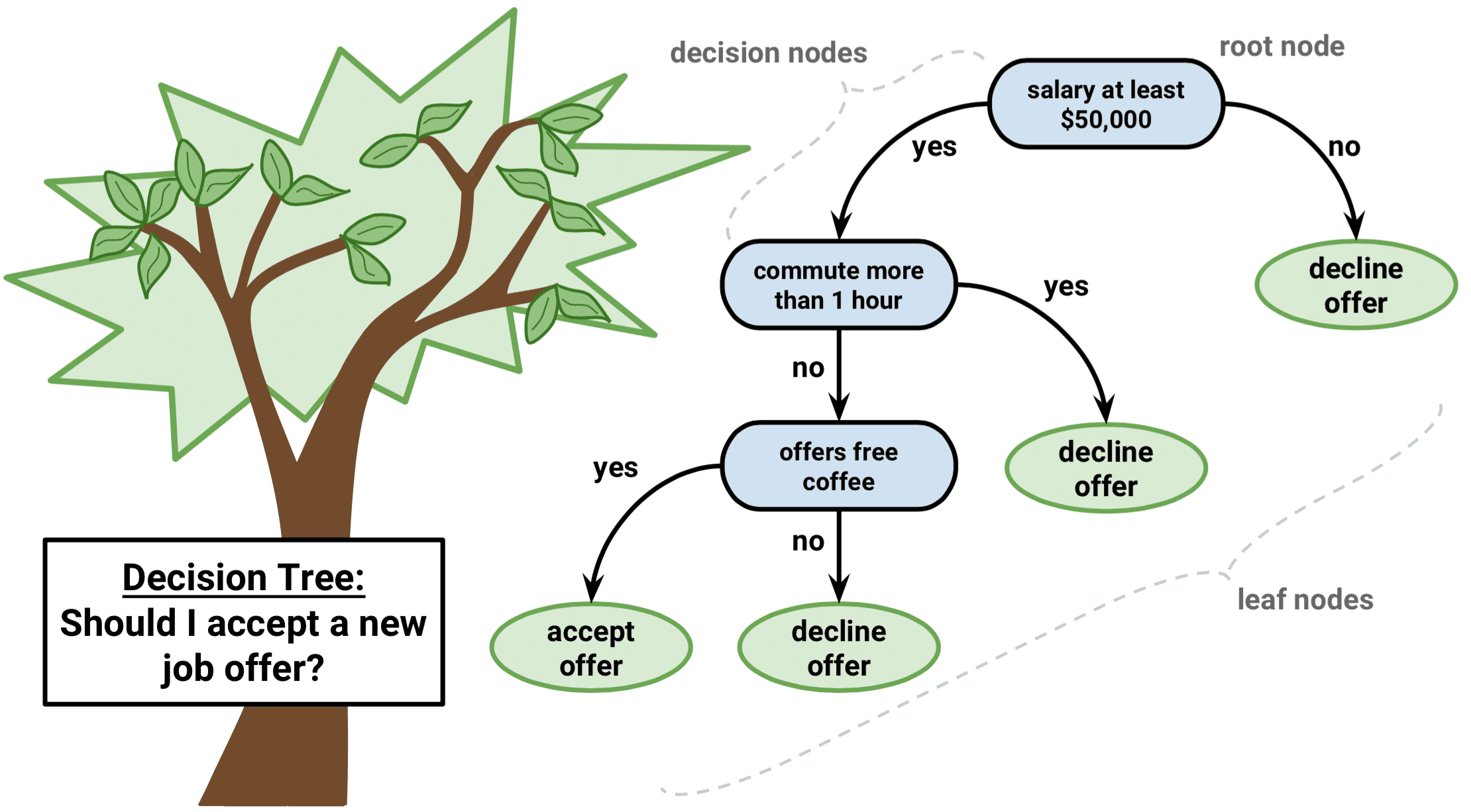
Trees are the support system of life and their structure has helped in defining many analogies. In machine learning, decision tree algorithm forms the crux of various complex algorithms.
Decision tree are a type of supervised algorithm which means the output depends on a set of defined data. It helps in building both classification or regression models in the form of a tree structure.
A decision tree can also be compared with a flow chart for a better understanding. The data is divided into subsets based on a particular attribute.
For example, a class of students could be divided on the base of gender or on the base of age. A decision tree consists of the following things:-
– an internal node which represents the result of the test
– Leaf node which represents a class label which is the decision made after computing all the attributes.
– The rules are represented the path from the root to the leaves.
Let’s go over a basic example for better understanding
this may be an over simplified example of a decision tree algorithm but it states the picture and purpose clearly. In simple words, a decision tree utilizes a tree structure to segment and streamline data into a model using if-else conditions at every step in order to arrive at a logical conclusion.
It does so by using the following methods-
– SPLITTING: The data is split into various subsets
– PRUNING: As the name suggest, this step involves reducing the size of tress by keeping only necessary data.
– TREE SELECTION: Finally, the tree which yields the lowest cross-validated error is selected.
Decision tree algorithms helps in communicating better and help one arrive at a suitable outcome. It is used in the following ways:-
– In finance for option pricing
– In remote sensing for pattern recognition
– In medical to find out trends of particular diseases.
2) K MEANS CLUSTERING ALGORITHM:-
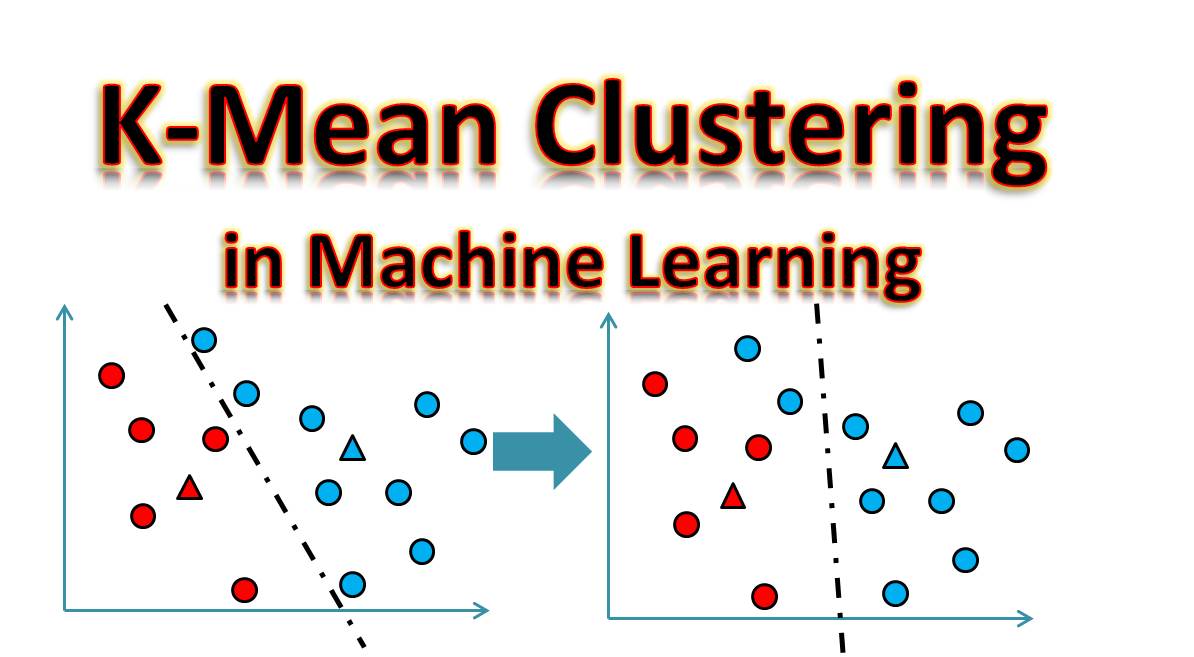
Let’s begin this with an example. Imagine you were on Wikipedia searching for “Apple”. An “apple” could be a fruit or the company. Wikipedia will give you all the web-pages that speak about apple – whether as a fruit or a software company. K Clustering algorithm will cluster all the web pages talking about “apple’ as a fruit in one cluster and remaining in the other cluster.
K-means is a type of unsupervised machine learning algorithm used for cluster analysis. K-Means is a non-determinative and iterative method. The algorithm works on a provided data set through pre-defined number of clusters, k. The output of K Means algorithm is k clusters with input data partitioned among the clusters.
This is hugely used in search engines to cluster web pages based on similarity which ultimately helps in reducing the computational type for uses
3) LINEAR REGRESSION:-
Let’s introduce this concept to you with a simple example, you are given a task of arranging items in ascending order of their weight. However, the weight of each item is not specified. Thus, you need to look at every item and assume their weight.
The entire arrangement will be based on your visual analysis and parameters. This is how Linear regression is.
A linear aggression is a relationship between an independent and dependent variable by fitting them to a line. This particular line is called regression line and is represented by equation Y = a*x+b.
In this equation:
- Y – Dependent Variable
- a – Slope
- X – Independent variable
- b – Intercept
The coefficients a & b are obtained by decreasing the sum of the squared difference of distance between data points and the regression line.
Liner aggression pays an important role in various business software, for eg
– It can help in estimating sales. By observing the trends of sales, one can forecast the sales of upcoming month with the help of linear aggression method.
– Similarly, insurance companies depend greatly in finding out the relevance of age groups. i.e., the senior citizens claim it more etc.
4) RANDOM FOREST ALGORITHM
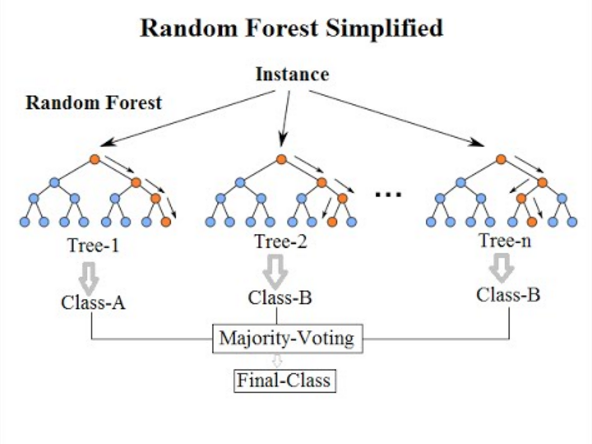
Random forest algorithm is a natural progression of a decision tree algorithm. As per Techopedia, “a random forest is a data construct applied to machine learning that develops large numbers of random decision trees analyzing sets of variables”.
Random forest algorithm helps in providing a more sophisticated analysis of data by enabling its viability through various possible cases. We all know that the denser the forest, the better for the environment. Similarly, when there’re more decision trees involved in arriving at a result, the outcome is more reliable and accurate.
For example, if you ask your sibling’s opinion about choosing a new mobile phone, he/she will ask few questions, make some assumptions about your liking and behavior and then, will suggest you a model. This is an example of a decision tree.
You may also ask your friends the same question and they will give you an answer depending upon their judgment of your choice. You will naturally go with the most recommended option. This explains the working of a random forest algorithm.
There are many real-life scenarios where this algorithm is useful. They are:
– Banking Sector: It helps in detecting fraud customers and transactions by tracking the transactional behavior.
– Medical Sector: This helps in predicting a patient’s condition based on their past medical records.
– Stock Market: This algorithm helps set up the trends and movement of stock prices in the market.
5) NAÏVE BAYES ALGORITHM
This algorithm is based on an assumption by the classifier that one particular feature in a class in unrelated to any other feature. They may be related to each other in reality, but the classifier would still consider them independent of each other for calculating a probability.
In order to calculate the probability of a hypothesis (h) being true, with our previous knowledge (d), this theorem is applied
P(h|d)= (P(d|h) * P(h)) / P(d)
where
- P(h|d) = Posterior probability. The probability of hypothesis h being true, given the data d, where P(h|d)= P(d1| h)* P(d2| h)*….*P(dn| h)* P(d)
- P(d|h) = Likelihood. The probability of data d given that the hypothesis h was true.
- P(h) = Class prior probability. The probability of hypothesis h being true (irrespective of the data)
- P(d) = Predictor prior probability. Probability of the data (irrespective of the hypothesis)
Lets take an example,
Let us find out the outcome play= ‘yes’ or ‘no’ given the value of variable weather=’sunny’, calculate P(yes|sunny) and P(no|sunny) and choose the outcome with a higher probability.
->P(yes|sunny)= (P(sunny|yes) * P(yes)) / P(sunny)
= (3/9 * 9/14 ) / (5/14)
= 0.60
-> P(no|sunny)= (P(sunny|no) * P(no)) / P(sunny)
= (2/5 * 5/14 ) / (5/14)
= 0.40
Thus, if the weather =’sunny’, the outcome is play= ‘yes’.
There are many practical applications for this algorithm. Some of them are –
– Facebook uses this to find out the happy and sad status updates.
– Helps in email spam filtering
– It is also used in classifying new articles about various topics.
– Google uses it for page rank mechanisms
CONCLUSION:
As per a research, machine learning algorithms will replace 10% data scientist jobs in the next 10 years. The only way to keep up with the mad world of data science and machine learning is to know the algorithms like the back of your hand.
In order to learn more about machine learning and its various aspects, feel free to drop us a comment and embark on your journey to figure out the mathematics behind data science and machine learning.
