What is Natural Language Processing? Intro to NLP in Machine Learning

NLP is a part of machine learning that deals with understanding, analyzing, and generating the languages that humans use naturally or communicate in order to interface with computers instead of machine language.
Applications of NLP
- Machine Translation – Google translate, etc.
- Language generation
- Sentiment Analysis
- Chatbots
- Web search
- Personal Assistants like Siri, Cortana, and Alexa, etc.
- Auto-complete: In search engines (e.g. Google, Bing).
- Spell-checking – Grammarly is a very good example of it.
- Many more….
NLP Pipeline
There are 3 stages of an NLP pipeline:
1. Text Processing:- Take raw text as input, clean it, normalize it, tokenize it, remove stop words, etc. and convert it into a form that is best for feature extraction.
2. Feature Extraction:- Extract features that are appropriate for an NLP task you are trying to accomplish and the model you are trying to use.
3. Modeling:- Design a machine learning model, fit its parameters to the training data, and then use it to make predictions on unseen data.
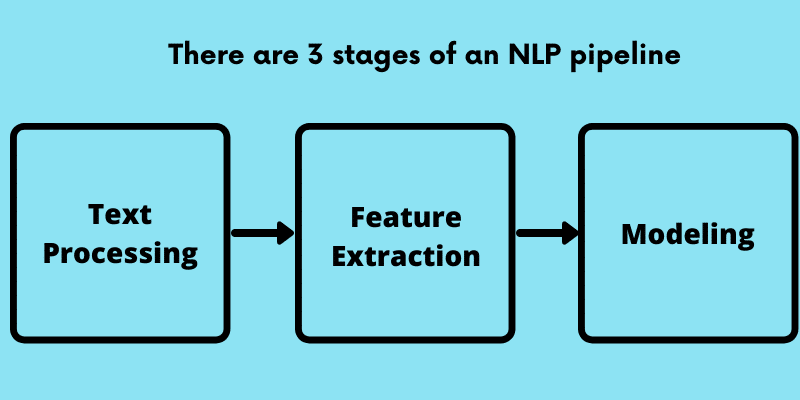
This process/pipeline isn’t always linear and may require additional steps.
Read also:- Regression vs classification in Machine Learning
Why do we need to process text?
To make our raw input text free from any constructs that are not required for the task.
- Extracting plain text – Extract plain text from pdf, documents, web, speech, scans, etc.
- Reducing complexity – Things like capitalization, punctuation, common words/stop words, etc. do not add much meaning to the text. Sometimes it’s best to remove that to reduce the complexity of the model you want to apply later.
Text Processing
Data Cleaning
Here we remove special characters, HTML tags, etc. from the raw text as they do not contain any info for the model to learn and are irrelevant or noisy data.
Data Normalization
Data normalization involves steps such as case normalization, punctuation removal, etc. so that the text is in a single format for the machine to learn.
Read More:- Is Python Enough for Machine Learning
Case Normalization
Car, car, CAR -> they all mean the same thing.
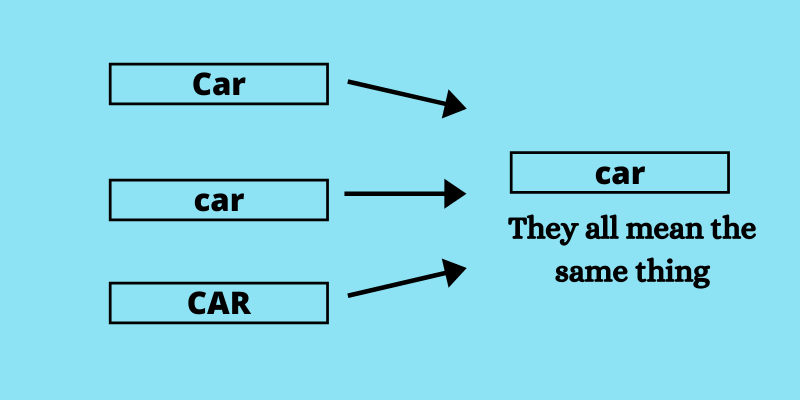
So, convert all capitalization to lower to bring to a common case.
1. # Convert text to lower case
2. text = text.lower()
3. print(text)
Punctuation Removal
Replace punctuation with space.
1. import re
2.
3. # Remove punctuation characters
4. text = re.sub(r"[^a-zA-Z0-9]", " ", text)
5. print(text)
Tokenization
Tokenization is the process of breaking up text documents into individual words called tokens.
1. # Split text into tokens (words)
2. # Splits based on whitespace
3. words = text.split()
4. print(words)
So, far we have been using python inbuilt functions for this task.
Tokenization using NLTK
1. import nltk
2. nltk.download('punkt') # required for tokenizer
3.
4. from nltk.tokenize import word_tokenize, sent_tokenize
5.
6. # Split text into words using NLTK
7. text = "Mr. Gyansetu graduated from IIT-Delhi. He later started an analytics firm called Lux, which catered to enterprise customers."
8. words = word.tokenize(text)
9. print(words)
10.
11. ## Output
12. ## ['Mr.', 'Gyansetu', 'graduated', 'from', 'IIT-Delhi', '.', 'He', 'later', 'started', 'an', 'analytics', 'firm', 'called', 'Lux', ',', 'which', 'catered', 'to', 'enterprise', 'customers', '.']
13.
14.
15. # Split text into sentences
16. text = "Mr. Gyansetu graduated from IIT-Delhi. He later started an analytics firm called Lux, which catered to enterprise customers."
17. sentences = sent_tokenize(text)
18. print(sentences)
19.
20. ## Output
21. ## ['Mr. Gyansetu graduated from IIT-Delhi.', 'He later started an analytics firm called Lux, which catered to enterprise customers.']
Stop Word Removal
Stop word removal means the removal of non-important words like ‘a’, ‘is’, ‘the’, ‘and’, ‘an’, ‘are’, “me”, “i”, etc.
There is an in-built stopword list in NLTK which we can use to remove stop words from text documents. However this is not the standard stopwords list for every problem, we can also define our own set of stop words based on the domain.
1. import nltk
2. nltk.download('stopwords') #corpora of stopwords (required for stopwords)
3. # List of stop words
4. from nltk.corpus import stopwords
5. print(stopwords.words("english"))
6.
7. ## Output
8. ## ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
9.
10. # Remove stop words
11. words = [w for w in words if w not in stopwords.words("english")]
12. print(words)
13.
14. ## Output
15. ## ['Mr.', 'Gyansetu', 'graduated', 'IIT-Delhi', '.', 'He', 'later', 'started', 'analytics', 'firm', 'called', 'Lux', ',', 'catered', 'enterprise', 'customers', '.']
Parts of Speech (POS) Tagging
Given a sentence, determine POS tags for each word (e.g., NOUN, VERB, ADV, ADJ).
You can use an inbuilt part of speech tagger provided in NLTK. There are other more advanced forms of POS tagging that can learn sentence structures and tags from given data, including Hidden Markov Models (HMMs) and Recurrent Neural Networks (RNNs).
1. import nltk
2. nltk.download('averaged_perceptron_tagger')
3.
4. from nltk import pos_tag
5.
6. # Tag parts of speech (PoS)
7. sentence = word_tokenize("I always lie down to tell a lie.")
8. pos_tag(sentence)
9.
10. ## Output
11. """
12. [('I', 'PRP'),
13. ('always', 'RB'),
14. ('lie', 'VBP'),
15. ('down', 'RP'),
16. ('to', 'TO'),
17. ('tell', 'VB'),
18. ('a', 'DT'),
19. ('lie', 'NN'),
20. ('.', '.')]
21. """
Named Entity Recognition
In information extraction, a named entity is a real-world object, such as persons, locations, organizations, products, etc., that can be denoted with a proper name.
1. import nltk
2. nltk.download('maxent_ne_chunker')
3. nltk.download('words')
4.
5. from nltk import pos_tag, ne_chunk
6. from nltk.tokenize import word_tokenize
7.
8. # Recognize named entities in a tagged sentence
9. out = ne_chunk(pos_tag(word_tokenize("Shalki joined Gyansetu Ltd. in Gurgaon.")))
10. print(out.__repr__())
11.
12. ## Output
13. ## Tree('S', [Tree('PERSON', [('Shalki', 'NNP')]), ('joined', 'VBD'), Tree('PERSON', [('Gyansetu', 'NNP')]), ('Ltd.', 'NNP'), ('in', 'IN'), Tree('GPE', [('Gurgaon', 'NNP')]), ('.', '.')])
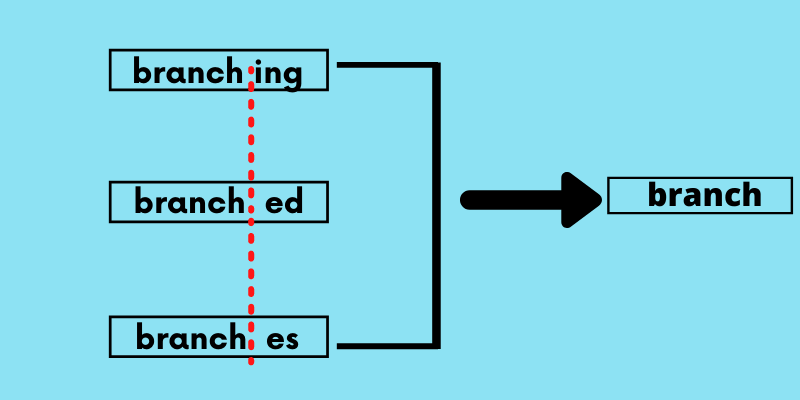
Stemming
Stemming is a process of reducing a word to its root form.
branching branched, branches can all be reduced to branch.
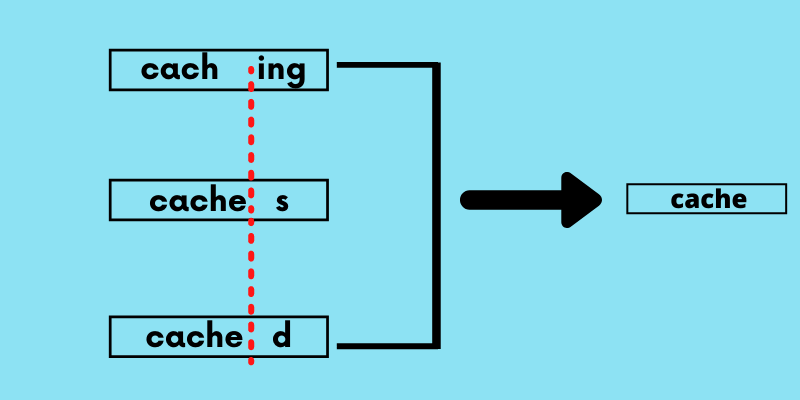
Caching, caches, cached can all be reduced to the cache.
1. from nltk.stem.porter import PorterStemmer
2.
3. # Reduce words to their stemmer
4. stemmed = [PorterStemmer().stem(w) for w in words]
5. print(stemmed)
6.
7. ## Output
8. ## ['mr.', 'gyansetu', 'graduat', 'iit-delhi', '.', 'He', 'later', 'start', 'analyt', 'firm', 'call', 'lux', ',', 'cater', 'enterpris', 'custom', '.']
Lemmatization
Lemmatization is another technique for reducing words to it’s normalized form. But in this case, the transformation actually uses a dictionary to map words to their actual form.
1. import nltk
2. nltk.download('wordnet')
3.
4. from nltk.stem.wordnet import WordNetLemmatizer
5.
6. # Reduce words to their root form
7. lemmed = [WordNetLemmatizer().lemmatize(w) for w in words]
8. print(lemmed)
9.
10. ## Output
11. ## ['Mr.', 'Gyansetu', 'graduated', 'IIT-Delhi', '.', 'He', 'later', 'started', 'analytics', 'firm', 'called', 'Lux', ',', 'catered', 'enterprise', 'customer', '.']
12.
13. # Reduce words to their root form
14. # default it will lemmatize noun forms, you can specify to lemmatize any other parts-of-speech
15. lemmed = [WordNetLemmatizer().lemmatize(w, pos='v') for w in words]
16. print(lemmed)
17.
18. ## Output
19. ## ['Mr.', 'Gyansetu', 'graduate', 'IIT-Delhi', '.', 'He', 'later', 'start', 'analytics', 'firm', 'call', 'Lux', ',', 'cater', 'enterprise', 'customers', '.']
change, changing, changes, changed, changer is transformed to change in Stemmed from (stemming does not confirm the root word is also a full actual word), but this is transformed to change in Lemmatized form (lemmatization will have the root word also as an actual meaningful word).
Learn Machine Learning
Feature Extraction
Feature Extraction is a way of extracting feature vectors from the text after the text processing step so that it can be used in the machine learning model as input. This extracted feature from the text can be a wordnet of a graph of nodes, a vector representing words (doc2vec, word2vec, sent2vec, glove, etc.)
Word Embedding is one such technique where we can represent the text using vectors. The more popular forms of word embeddings are:
1. BoW, which stands for Bag of Words
2. TF-IDF, which stands for Term Frequency-Inverse Document Frequency
Bag-of-Words Model
Bag of words model, or BoW for short, is a way of extracting features from the text for use in modeling, such as machine learning algorithms. It treats each document as a collection/bag of words.
A bag-of-words is a representation of text that describes the occurrence of words within a document. It involves two things:
- A vocabulary of known words in the corpus/set of documents.
- A measure of the presence of known words.
The intuition is that documents are similar if they have similar content. Further, from the content alone we can learn something about the meaning of the document.
Example:-
- If you want to compare essays submitted by students for plagiarism, there each essay will be considered as a document.
- If you want to analyze the sentiments submitted in the tweets, then there each tweet will be considered as a document.
Corpus is a set of documents.
TF-IDF
Let’s first put a formal definition around TF-IDF. Here’s how Wikipedia puts it:
“Term frequency-inverse document frequency is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.”
Term Frequency
Let’s first understand Term Frequent (TF). It is a measure of how frequently a term, t, appears in a document, d
Here, in the numerator, n is the number of times the term “t” appears in the document “d”. Thus, each document and term would have its own TF value.
Inverse Document Frequency (IDF)
IDF is a measure of how important a term is. We need the IDF because computing just the TF alone is not sufficient to understand the importance of words.
Modeling
The final stage of the NLP pipeline is modeling, which includes designing a statistical or machine learning model, fitting its parameters to training data, using an optimization procedure, and then using it to make predictions about unseen data.
The nice thing about working with numerical features is that it allows you to choose from all machine learning models or even a combination of them.
Some of the machine learning algorithms used here are:-
1. Linear Regression
2. Logistic Regression
3. Decision Trees
4. Random Forest Classifier
5. Naive Bayes Classifier
6. Support Vector Machines (SVM)
7. Neural Networks (RNN, LSTM, Bi-LSTM)
8. Ensemble Methods – Adaboost, XGBoost, Gradient Boost
9. Gradient Boosting Machine
10. Nearest Neighbors (K-Nearest Neighbors, Approximate Nearest Neighbors, etc.)
11. Clustering (K-means, Hierarchical, DBSCAN, Gaussian Mixture Models, etc.)
12. Many more….
Once you have a working model, you can deploy it as a web app, mobile app, or integrate it with other products and services. The possibilities are endless!
